After 5-6 years of working on portal applications I've learned a lot of painful lessons, there's no reason you should have to suffer too. When I say "portal" I'm referring to the large boring enterprise portals that large boring companies build to try and consolidate all their applications into one web interface. IBM WebSphere Portal, Liferay Portal, Oracle Portal (WebLogic), and Microsoft Sharepoint are the biggest players in this space. Chances are you're trying to implement one right now.
When you start planning your first portal implementation you'll undoubtedly read volumes about best practices and so on. That's fine and everything but if there's only one design rule you follow please let it be this one - assume every single thing you integrate with is completely unreliable and will go down on a regular basis.
What's that? You say I'm all bitter and jaded? I'm sorry to say I'm being completely realistic. It took a few years for me to have this epiphany.
I was introduced to portal, specifically IBM WebSphere Portal, in 2006. For the purposes of this article the portal platform doesn't matter. The pitfalls are all exactly the same. I was the lead developer for the company's de-facto sales portal which was an ASP .NET site that primarily hosted content and provided some minimal single sign-on (SSO) to the dozens of other applications our sales force used.
Some VP, who made significantly more than any us, decided that we had to combine all these dozens of applications into a single portal. As the lead developer for the de-facto portal I was tasked with becoming an expert on WebSphere Portal and then training the rest of the team.
Without dumping my entire resume here I'll just say that from 2006-2009 I led development for migrating dozens of sales and reporting applications to our shiny new portal. From 2010-2011 I led an effort at the same company to migrate a myriad of call center desktop applications to another shiny new portal. Along the way I learned more than I ever wanted to about troubleshooting technology problems. In January 2012 I left for a senior architect position at a different company. After 5 years with WebSphere Portal I decided it was time to move on to something different. Although lately I have been tricked into a couple Liferay projects.
Alright, street creds are out of the way let's continue. So if you're reading this then chances are some VP at your company decided to move everything to a portal. You probably have a technology landscape that looks something like this:
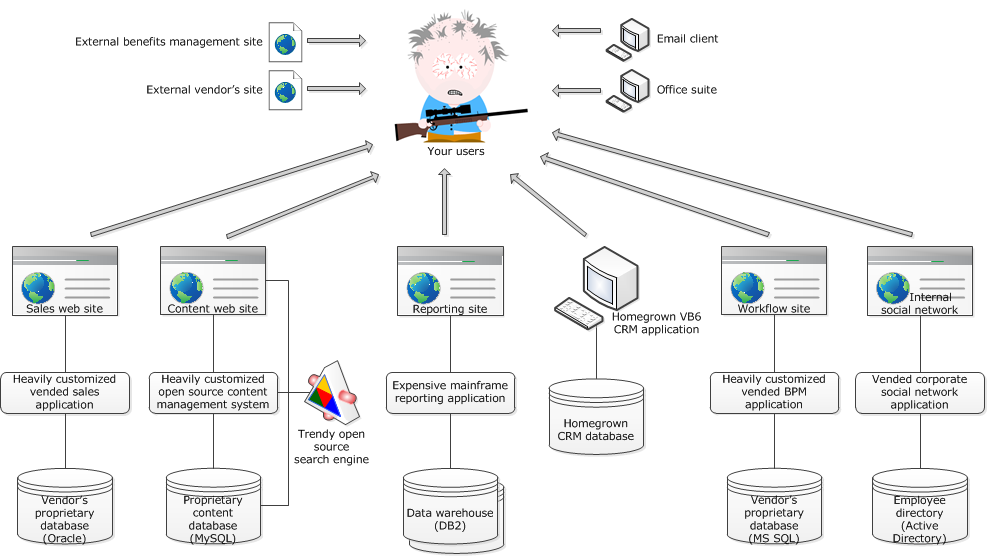
And you're the lucky chump, or chumpette, who's been given instructions to make it look like this:
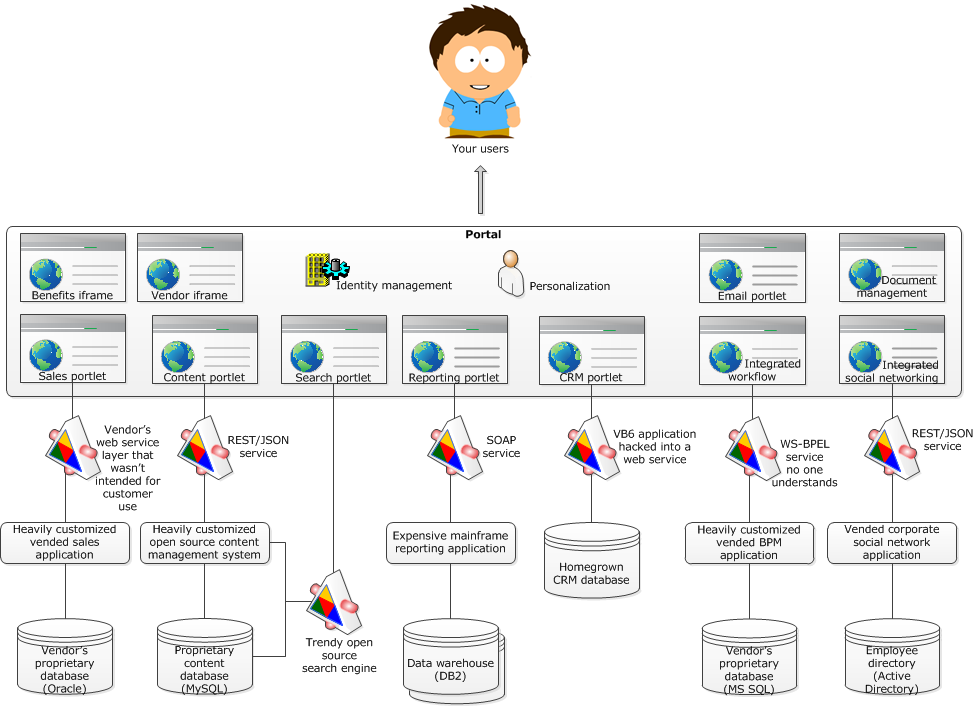
For the record I also think it's a terrible user experience to throw dozens of different applications at your users. Re-skinning them as portlets creates the illusion of an integrated system but all the underlying disfunctions are still there.
There's no time to do this right though. The VP made all kinds of crazy promises to the board of directors that this would be done in under twelve months. His bonus is counting on it so get to work already.
So we still have a lot of technologies that might work well on their own but are completely unproven in an integrated environment. Although they're used regularly they're not used constantly. The report users check once a day will see a dramatic increase in traffic once it's on the portal home page. Is it durable enough to handle the increased load?
For me almost everything comes down to a video game analogy. Heck, you probably found my site which searching for Mortal Kombat II or whatever. So to me, building a durable portal application is a lot like this old Bridge Builder game from 2000.
As the name implies it's a bridge building simulation. Being a free game it was pretty low-tech. The graphics were crude even compared to other games of its age. None of that mattered, it's still a way better game than I could ever hope to create and the fun was in finding the best way to solve each stage.
It all starts simply enough, just get a train across this tiny river:
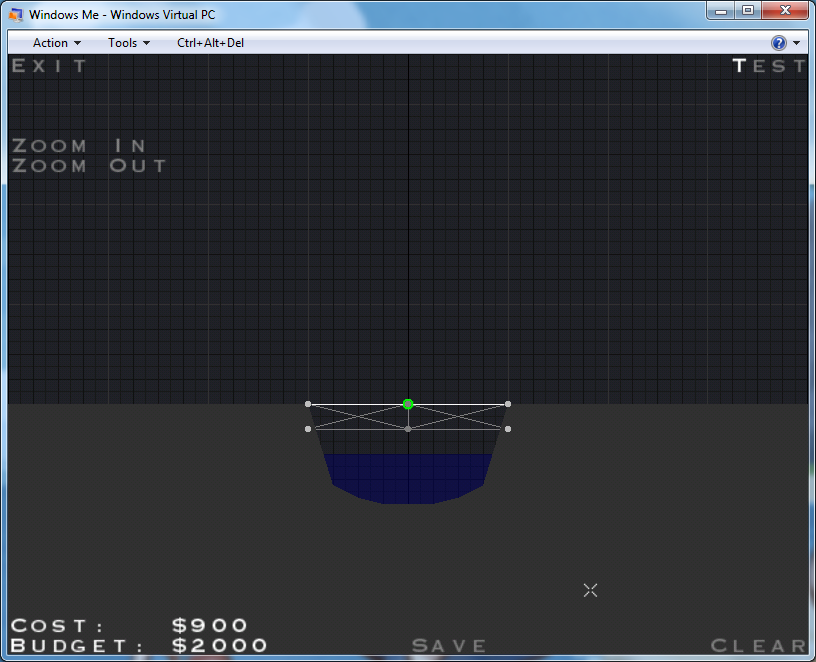
Sure is an easy problem to solve. All you need is a couple beams to keep the whole thing up. No complicated suspension, no redundant support, just slap a few things together quickly.
It's a lot like building a specialized, single-use web application. A request comes in "we need a web page to [run reports | show some marketing stuff | enroll people in something | etc..]"
So the application gets built and you slap together a web server & database to host it. It's a pretty lightweight infrastructure but hey it's a tiny river you need to cross. As long as these two things hold up everything will be fine:
Choo-choo here come your users:
There are some signs of light stress but everything works. It's so easy to keep an application up & running when it has few dependencies.
What about an application that's dependent not on two systems but on dozens? What about something, like portal, that's integrating all the applications users access at the same time?
Now you have giant bridge supported by many, many individual pillars:
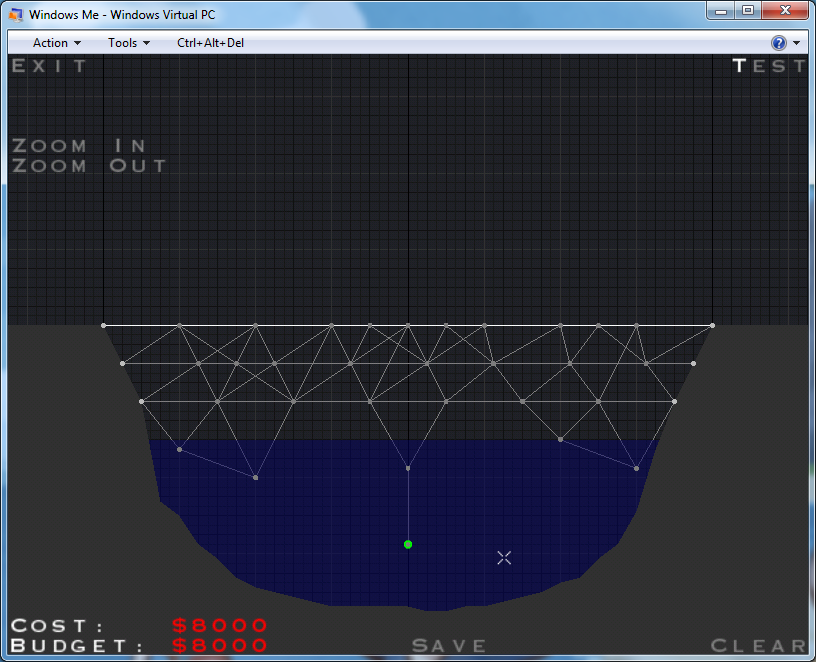
Each of these beams represents a system portal is calling or something that system is dependant on. There are even parts that aren't really doing anything. Chances are at your company that means some or all of the following:
-Vended applications that are at least one major release out of date
-Homegrown Java and .NET applications
-Legacy applications in VB6 that were last updated for Y2K
-Mix of SQL Server, Oracle, and DB2 database
-Active Directory and/or another directory service
-Expensive middleware product like Tibco
These are probably just some of the many systems that your portal is dependant on to function. Even if they all have 99.9% uptime you're still screwed. If your portal calls as few as 5 web services on the home page each with 99.9% uptime (including their numerous backend dependencies). That leaves you with 99.00% uptime across all of them, or 1.68 hours of downtime per week.
If any of these systems fails then you'll be getting a "portal is down" phone call. OK, portal itself may not actually be down but some really important functions might not work. Maybe the thing that's down is just cosmetic, maybe it's key to your sales process. To the end-user, and definitely the VP that dreamed this up, portal is "down".
Every single part of this portal bridge has to stay up 100% of the time or our proverbial train of users are goners. Here come some now, things aren't looking so hot:
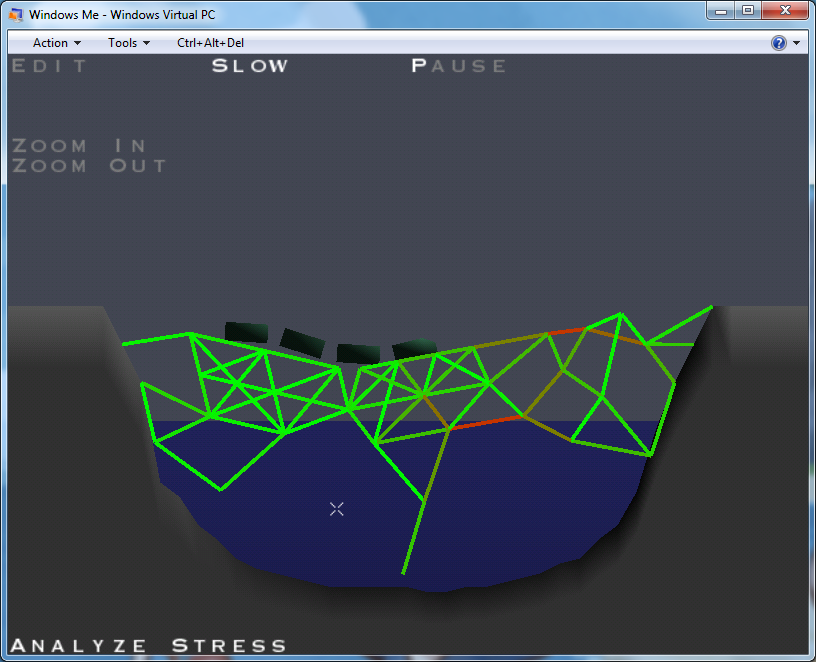
Oh, the humanity!
Sure a lot of parts stayed green but it doesn't matter to the end-user who's currently trying to swim out of a small window.
This leads us back to the most important design rule for portal applications - assume every single thing you integrate with is completely unreliable and will go down on a regular basis - because just one thing breaking is enough to take down the entire system.
I know this sounds bizarre to most enterprise architects and developers. After all, your in-house team builds the most stable web services ever to grace a data center and your DBAs guarantee 100% availability. It seems unfathomable that anything under your control could ever fail. Trust me on this one, everything you've built or installed will fail eventually if not regularly.
So what does this translate to in terms of actionable defensive measures?
1) Put a load balanced URL in front of everything you call. Even if there's only a single server behind it. Don't worry, there will be a second after it fails during your peak business hour.
If I ever convert this to a presentation, here's the graphic I'll use:
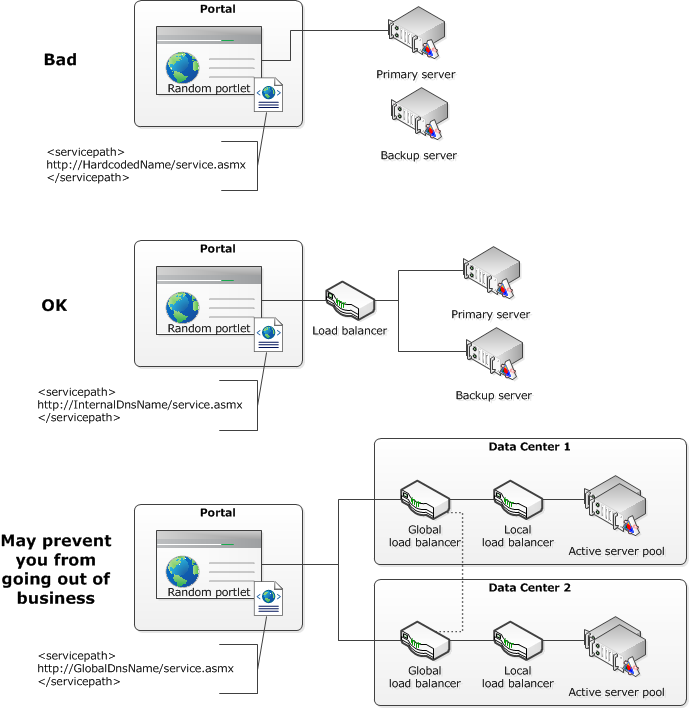
2) If you only have one server running a back-end service or database get a second. If you have two get a third. Repeat until someone tells you to stop spending money. This is obviously closely tied to the previous measure, without taking the previous measure though this one is useless.
3) Enable extremely aggressive timeouts on all back-end calls. If you call a service 1,000 times an hour and 1/1000 times it takes 30 seconds to respond it sucks for that user. If it has a bad day and 1000/1000 calls take 30 seconds you'll have a stuck thread pool. Threads are a shared resource, this one bad service can kill the entire portal. Go ahead and set the timeout on that call to 10 seconds, or better yet 5. How you do this varies by platform but they all support it.
If parallel portlet rendering is an option for you go ahead and use it. I say "if" because depending on which portal server and hardware you're running it might not be possible. From a user experience standpoint seeing something is always better than seeing nothing.
Here's a little picture to help illustrate the advantages of setting timeouts and using parallel portlet rendering. In this example we want all portlets on a page to respond within 3 seconds - green portlets are under that goal, yellow hit it exactly, and red are taking longer. The red '(X)' means the portlet rendering was terminated by a timeout.
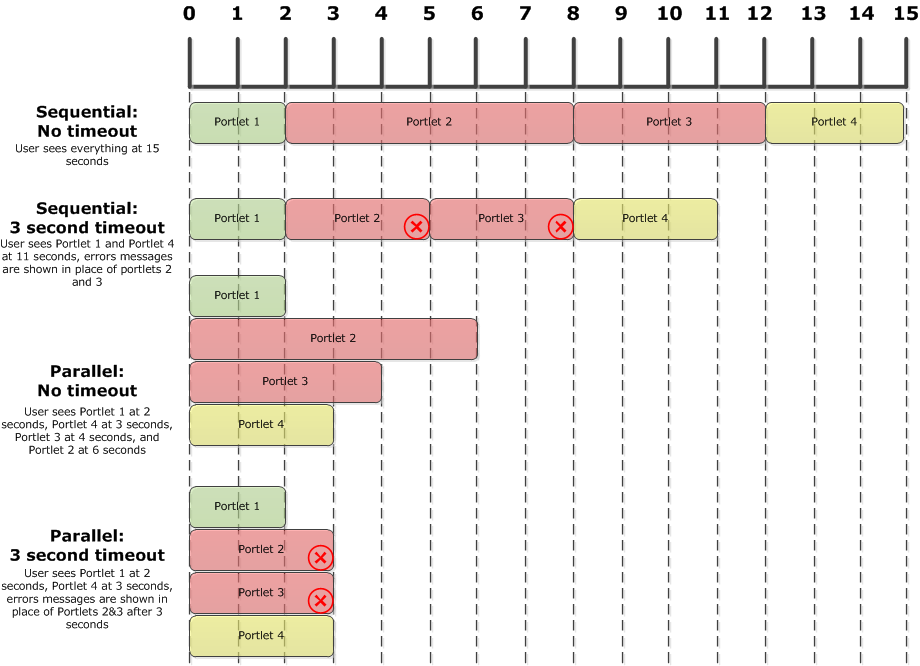
Yes, people will complain about this, a lot. Users will complain whenever a portlet says "sorry this is temporarily unavailable". They'll complain louder when the entire portal is down though. Application owners will complain that you're being unfair by expecting their service to respond in under 3 seconds 100% of the time. They're not the ones taking the phone call when portal is down, their opinion doesn't matter.
And this is where I'll leave things for now, stayed tuned for Part 2: Everyone Hates You and that's OK.